Our offices are located in Warsaw, Wroclaw, Poznan, Katowice as well as Munich, Frankfurt, Prague and Hradec Kralove.
Data Engineer
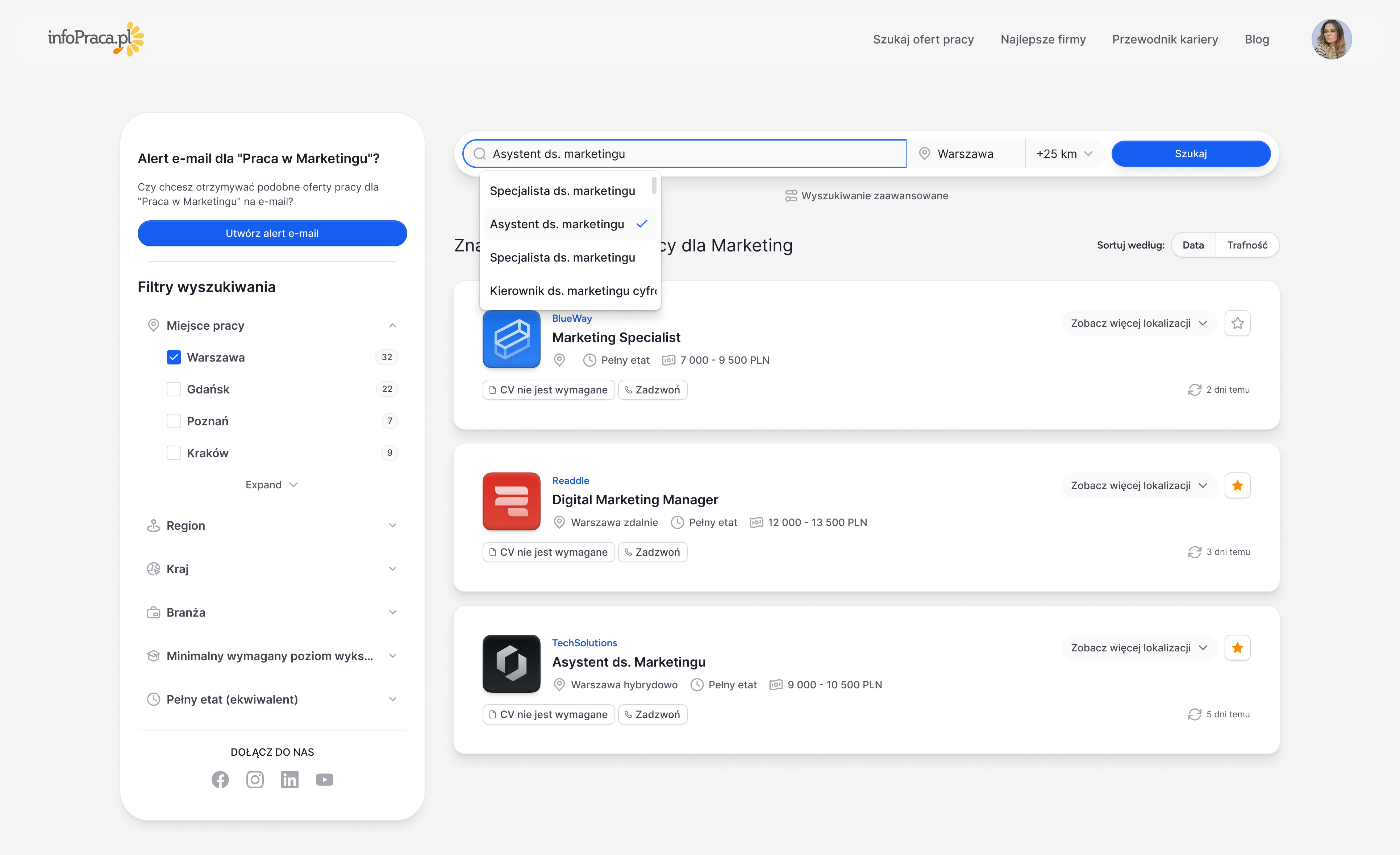
Location: WarszawaFor one of our client, a company from the IT industry, which provides IT services in the area of: IT security, hosting of system resources, remote management of IT resources and application services to one of the biggest international financial group, we are looking for…
DATA ENGINEER
… to join Advanced Analytics team dedicated to combine Big Data technology with Data Science.
Company / team overview:
- Industry recognized strong brand with positive recognition from customers in many countries;
- Strong financial position, omni-channel distribution strategy and international network;
- Freedom to innovate, true Agile approach;
- Committed to deliver stable and secure services to end users;
- Advanced Analytics team of 40 people who combine Big Data technology with Data Science to deliver high value solutions and products;
- Fun and creative environment!
Key functions / responsibilities:
- Work with the latest and greatest technologies in the field of Data Engineering;
- Developing and maintaining Data platform, further development the architecture of this platform and create new architectures for incoming projects;
- Laying the architectural foundations for the things you’re working on;
- Combining DB sources in real-time, distributed systems to handle large amounts of data loads in no-time;
- Close cooperation with:
- Data Scientists and Analysts - to find the best way to get their models to run in production, leading the way in how to aggregate the data and process it efficiently for each model;
- Business - to ingest new sources, cleaning and preparing the data and writing the code that connect it to your application;
- Work in a team with highly skilled people and enjoy a creative atmosphere where trying things out is encouraged.
Requirements:
- Solid experience working with following technologies and frameworks: Airflow, Spark;
- Hands-on experience managing and further developing distributed systems and clusters for both batch as well as streaming data (Hadoop/Spark and/or Kafka/Flink)
- Hands-on experience building complex data pipelines e.g. ETL
- Knowledge of at least one programming language: e.g. Python or Scala
- It would be highly appreciated if you have knowledge and experience in following areas:
- Data manipulation and transformation, e.g. SQL and setting up both SQL as well as noSQL databases (i.e. Cassandra)
- Deployment and provisioning automation tools e.g. Docker, Kubernetes, Openshift, CI/CD
- Bash scripting and Linux systems administration
- Security, authentication and authorization (LDAP / Kerberos / PAM)
- Affinity with Advanced Analytics, Data Science
- Other programming languages: scripting (Ruby, Groovy, …) or statically typed languages (Java, C++, Go, …)




Opis stanowiska
For one of our client, a company from the IT industry, which provides IT services in the area of: IT security, hosting of system resources, remote management of IT resources and application services to one of the biggest international financial group, we are looking for…
DATA ENGINEER
… to join Advanced Analytics team dedicated to combine Big Data technology with Data Science.
Company / team overview:
- Industry recognized strong brand with positive recognition from customers in many countries;
- Strong financial position, omni-channel distribution strategy and international network;
- Freedom to innovate, true Agile approach;
- Committed to deliver stable and secure services to end users;
- Advanced Analytics team of 40 people who combine Big Data technology with Data Science to deliver high value solutions and products;
- Fun and creative environment!
Key functions / responsibilities:
- Work with the latest and greatest technologies in the field of Data Engineering;
- Developing and maintaining Data platform, further development the architecture of this platform and create new architectures for incoming projects;
- Laying the architectural foundations for the things you’re working on;
- Combining DB sources in real-time, distributed systems to handle large amounts of data loads in no-time;
- Close cooperation with:
- Data Scientists and Analysts - to find the best way to get their models to run in production, leading the way in how to aggregate the data and process it efficiently for each model;
- Business - to ingest new sources, cleaning and preparing the data and writing the code that connect it to your application;
- Work in a team with highly skilled people and enjoy a creative atmosphere where trying things out is encouraged.
Requirements:
- Solid experience working with following technologies and frameworks: Airflow, Spark;
- Hands-on experience managing and further developing distributed systems and clusters for both batch as well as streaming data (Hadoop/Spark and/or Kafka/Flink)
- Hands-on experience building complex data pipelines e.g. ETL
- Knowledge of at least one programming language: e.g. Python or Scala
- It would be highly appreciated if you have knowledge and experience in following areas:
- Data manipulation and transformation, e.g. SQL and setting up both SQL as well as noSQL databases (i.e. Cassandra)
- Deployment and provisioning automation tools e.g. Docker, Kubernetes, Openshift, CI/CD
- Bash scripting and Linux systems administration
- Security, authentication and authorization (LDAP / Kerberos / PAM)
- Affinity with Advanced Analytics, Data Science
- Other programming languages: scripting (Ruby, Groovy, …) or statically typed languages (Java, C++, Go, …)
Dodatkowe informacje
- Ostatnia aktualizacja
- Wymiar etatu
- Pełny etat
- Rodzaj umowy
- Na czas nieokreślony
- Liczba wakatów
- 1
- Min. doświadczenie
- Bez doświadczenia
- Min. wykształcenie
- Wyższe inżynierskie
- Branża / kategoria
- Praca IT - Programowanie / Analizy